Data Freshness and Expiration
Data Freshness
Data freshness refers to how up-to-date a copy of data (e.g. in a cache) is compared to the source version of the data (e.g. in the system-of-record (SoR)). A stale copy is considered to be out of sync (or likely to be out of sync) with the SoR.
Databases (and other SORs) weren’t built with caching outside of the database in mind, and therefore don’t normally come with any default mechanism for notifying external processes when data has been updated or modified. Thus external components that have loaded data from the SoR have no direct way of ensuring that data is not stale.
Cache Entry Expiration
Ehcache can assist you with reducing the likelihood that stale data is used by your application by expiring cache entries after some amount of configured time. Once expired, the entry is automatically removed from the cache.
For instance the cache could be configured to expire entries five seconds after they are put into the cache - which is a time-to-live TTL setting. Or to expire entries 17 seconds after the last time the entry was retrieved from the cache - which is a time-to-idle TTI setting.
The expiration configuration that would be most appropriate for your cache (if any) would be a mixture of a business and technical decision based upon the requirements and assumptions of your application.
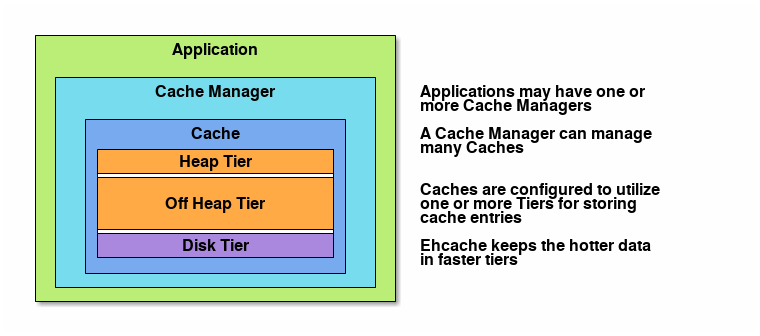
Storage Tiers
You can configure Ehcache to use various data storage areas.
When a cache is configured to use more than one storage area, those areas are arranged and managed as tiers.
They are organized in a hierarchy, with the lowest tier (farther) being called the authority tier and the others being part of the caching tier (nearer, also called near cache) .
The caching tier can itself be composed of more than one storage area.
The hottest data is kept in the caching tier, which is typically less abundant but faster than the authority tier.
All the data is kept in the authority tier, which is slower but more abundant.
Data stores supported by Ehcache include:
-
On-Heap Store - Utilizes Java’s on-heap RAM memory to store cache entries. This tier utilizes the same heap memory as your Java application, all of which must be scanned by the JVM garbage collector. The more heap space your JVM utilizes, the more your application performance will be impacted by garbage collection pauses. This store is extremely fast, but is typically your most limited storage resource.
-
Off-Heap Store - Limited in size only by available RAM. Not subject to Java garbage collection (GC). Is quite fast, yet slower than the On-Heap Store because data must be moved to and from the JVM heap as it is stored and re-accessed.
-
Disk Store - Utilizes a disk (file system) to store cache entries. This type of storage resource is typically very abundant but much slower than the RAM-based stores. As for all application using disk storage, it is recommended to use a fast and dedicated disk to optimize the throughput.
-
Clustered Store - This data store is a cache on a remote server. The remote server may optionally have a failover server providing improved high availability. Since clustered storage comes with performance penalties due to such factors as network latency as well as for establishing client/server consistency, this tier, by nature, is slower than local off-heap storage.
Topology Types
Standalone
The data set is held in the application node. Any other application nodes are independent with no communication between them. If a standalone topology is used where there are multiple application nodes running the same application, then their caches are completely independent.
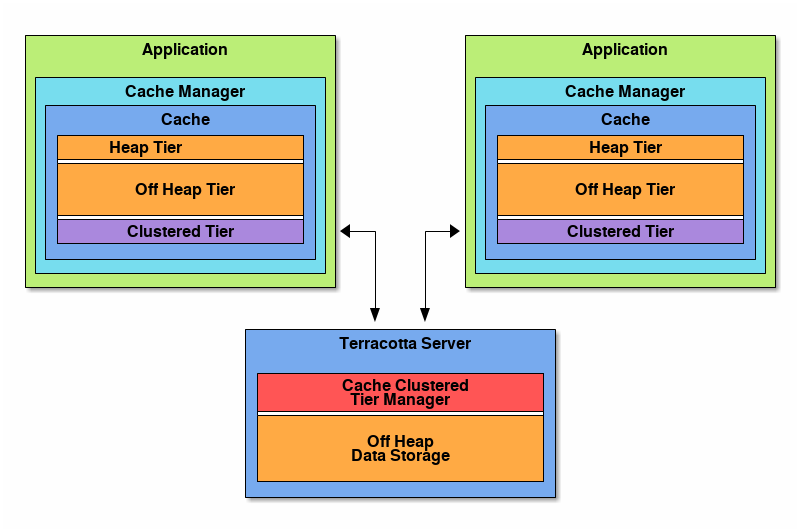
Distributed / Clustered
The data is held in a remote server (or array of servers) with a subset of hot data held in each application node. This topology offers offers a selection of consistency options. A distributed topology is the recommended approach in a clustered or scaled-out application environment. It provides the best combination of performance, availability, and scalability.
-
Hot data is cached locally, hotter data in faster tiers
-
Data cached by one application instance is available to all cluster members.
-
Full data is available in the cluster.
-
One or more mirror servers may be deployed to provide HA
It is common for many production applications to be deployed in clusters of multiple instances for availability and scalability. However, without a distributed cache, application clusters exhibit a number of undesirable behaviors, such as:
-
Cache Drift - If each application instance maintains its own cache, updates made to one cache will not appear in the other instances. A distributed cache ensures that all of the cache instances are kept in sync with each other.
-
Database Bottlenecks - In a single-instance application, a cache effectively shields a database from the overhead of redundant queries. However, in a distributed application environment, each instance must load and keep its own cache fresh. The overhead of loading and refreshing multiple caches leads to database bottlenecks as more application instances are added. A distributed cache eliminates the per-instance overhead of loading and refreshing multiple caches from a database.